
 火星电竞·(CHINA)官方网站
火星电竞·(CHINA)官方网站
新智元报说念

【新智元导读】太荒诞了!一个连官网都莫得的玄妙中国AI「扫地僧」,以73.1%的胜率杀入CyberGym全球前七,紧咬OpenAI。全网都在疯传,这到底是谁家的高东说念主?
这几天,在全球AI巨头拼杀正酣的一张榜单上,倏得多了一个谁都没听过的名字。
它叫MopMonk(扫地僧)。
莫得雷厉风行的发布会,莫得官博长文,莫得酬酢媒体上的逆风招展。
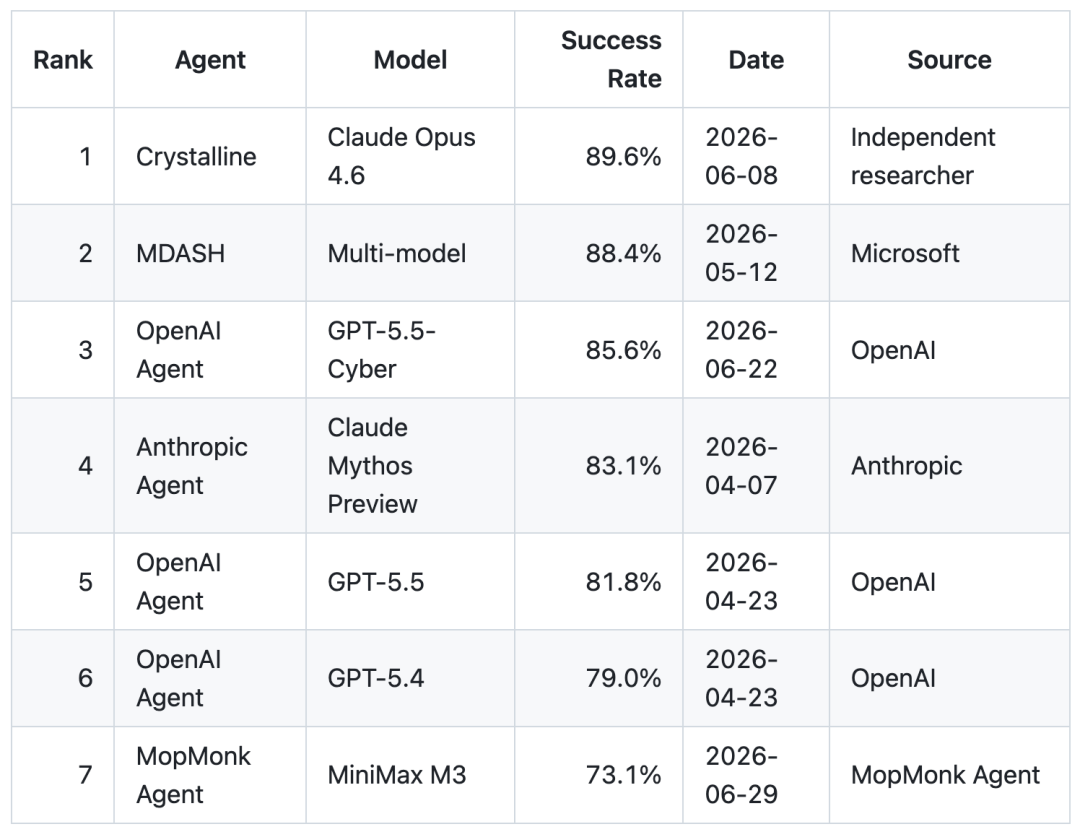
它就这样诬捏出世,直接杀入CyberGym全球前十。
凭借73.1%的得胜率,以狭窄差距紧咬OpenAI,一举刷新了中国团队在该榜单上的历史最高分。
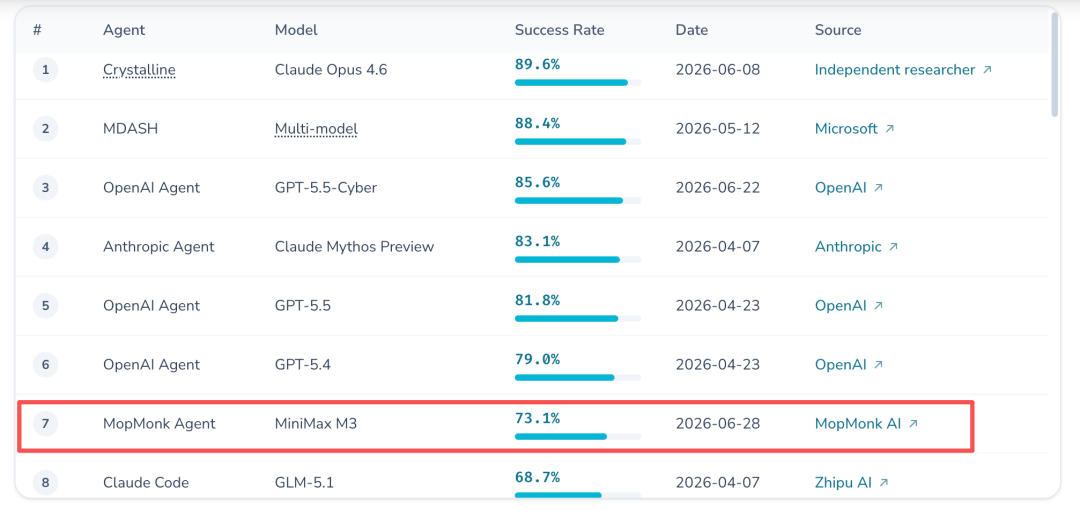
整件事最玄幻的所在在于,时于本日,无东说念主清爽它的真面庞。
CyberGym这份榜,到底有多重?
MopMonk此次的获利究竟有多炸裂?望望它所站上的擂台就知说念了。
CyberGym,由UC Berkeley团队倾力打造,中枢论文中选ICLR 2026顶会。

传送门:https://arxiv.org/pdf/2506.02548
作为AI收罗安全智力评估范围最巨擘的公开基准之一,这里号称大模子的「修罗场」——
就连GPT-5.5-Cyber、Claude Mythos这种级别的顶流,都曾在这个榜单里贴身肉搏。
所有这个词基准主打「真枪实弹」:
1507个漏洞实例、188个开源大名目,所有考题一都扒自Google OSS-Fuzz千里淀下来的真实历史漏洞。

从评估维度来看,这是一个跨量级的打破。
它的体量,是此前最大公开基准(NYU CTF,约200题)的足足7.5倍,更是把CVE-Bench这种「前辈」直接甩出了一个数目级。
更要命的是难度,CyberGym不作念采用题。
它要求AI在动辄数千个文献、数百万行代码的真实名目里,完成深度推理。
正因为富余大、富余真、富余难,CyberGym才有了「分手度」——
它能把不同模子、不同Agent框架之间那点真实的智力差距,一刀一刀地切出来。
难怪安全圈,直接将其封为「AI安全范围的奥运会」。
也正因如斯,全球头部玩家险些全员到场,微软、OpenAI、Anthropic、谷歌、Meta、智谱……
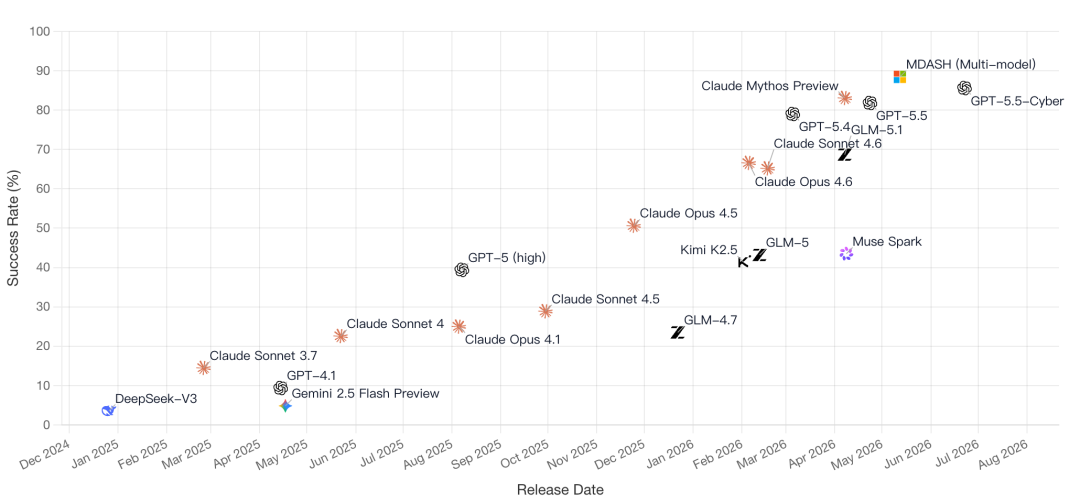
CyberGym榜单自己,正在见证AI竞争的一次要津转向:
从比谁参数大,转向比谁的Agent真能把活干完。
一个生疏的东方代号
倏得出当今硅谷AI巨头中间
谁能意象,恰正是在这个最靠「硬实力」话语的擂台上,杀出了一匹「查无此东说念主」的黑马。
拨开迷雾,咱们目前掌捏的已知谍报仅有三条:
玄妙代号:MopMonk(扫地僧)
基座模子:MiniMax M3
榜单战绩:杀进CyberGym全球第七,中国第一
按常理,打出这种获利的团队,技巧论述和新闻发布会早该声势汹汹。
可在这份高东说念主云集的榜单上,MopMonk偏巧是阿谁最透彻的「异类」:只甩出一份技巧论述,团队、公司、坐标,一概查无此东说念主。
这种「实力顶配,信息裸奔」的碰撞,自己就充满了一种东方武侠式的戏剧性。
熟谙金庸的东说念主,都懂《天龙八部》中「扫地僧」这三个字的重量——
少林藏经阁里阿谁扫了几十年地、没东说念主谨记姓名的老梵衲,一开端却镇住了萧远山、慕容博两大高东说念主。
最不起眼的变装,藏着最深的功夫。

敢顶着「扫地僧」的名号踢馆,这支团队彰着对我方的实力,有着极其冷情的自信!
更要津的陈迹,覆盖在它的技巧底层——MopMonk选用的基座,是MiniMax M3。
作为一个来自上海的开源基座,M3号称六边形战士,直接集都了三大中枢杀器:前沿的编程智力、1M超长高下文,以及原生多模态。
一边是极具东方颜色的「文化标记」,另一边是打着隧说念国产标签的技巧底座。
把这两条陈迹摆上桌面,圈子依然收得很小了。所有的蛛丝马迹都在荒诞默示并吞个论断:
这大要率是一支中国战队。
赢输手,在Harness
抛开身份悬念,作为恒久跟踪AI技巧的东说念主,咱们更想搞昭彰一个问题:
MopMonk凭什么赢?
要回复这个问题,得先回到CyberGym最难的阿谁中枢——它考的根柢不是「知不知说念」,而是「作念不作念得回」。
判断一段代码有莫得漏洞,对今天的大模子来说依然不算太难。
但CyberGym要考的是下一步、亦然最要命的那一步:生成一个能触发漏洞的输入,也便是PoC。
它必须在「有漏洞的版块」上触发,在「已诞生的版块」上失效,并通过基准环境的实施考证。
这说念坎,远比想象中顽恶。
漏洞的触发条目,经常衰败地藏在代码旅途、贯通逻辑、构建环境、测试Harness和输入神气之间,得少量点拼出来。
更坑的是,哪怕PoC在土产货把规律跑崩了,也无意算数。只消不可舒适「漏洞版触发、诞生版不触发」的差分判定,照样白忙一场。

这一步,把任务从「长入」透彻拽进了「实施」。况兼是一种很特地的实施——
整场考试,是在一个禁闭、断网的环境里进行的。
莫得外部搜索不错求援,莫得任何「场外资源」,AI能依靠的,惟一双咫尺这套代码库的长入,和它我方一步步攒下来的操心。
要在这种条目下把漏洞「复现」出来,靠的是一整套丝丝入扣的智力:
用具调用狡计:什么时候该读文献、什么时候该跑测试、什么时候该回头改决策;
多轮推理:上一次没触发,问题到底出在哪,下一次该怎么养息;
操心处理:把读过的代码、试过的输入、踩过的坑结构化地存下来,而不是每一轮都从零再读一遍;
迭代考证:一遍遍面对阿谁临界点,直到漏洞果真被复现。
换句话说,CyberGym较量的中枢,是Agent的「行能源」,模子的「智力」仅仅入场券。
而把「机灵」形成「行能源」的阿谁要津武艺,便是今天所有这个词Agent范围最被低估的一个词——Harness。
Harness,是模子与外部用具、实施环境之间的「合作层」。
它负责用具编排、高下文情状处理、实施响应的回收与再投喂。
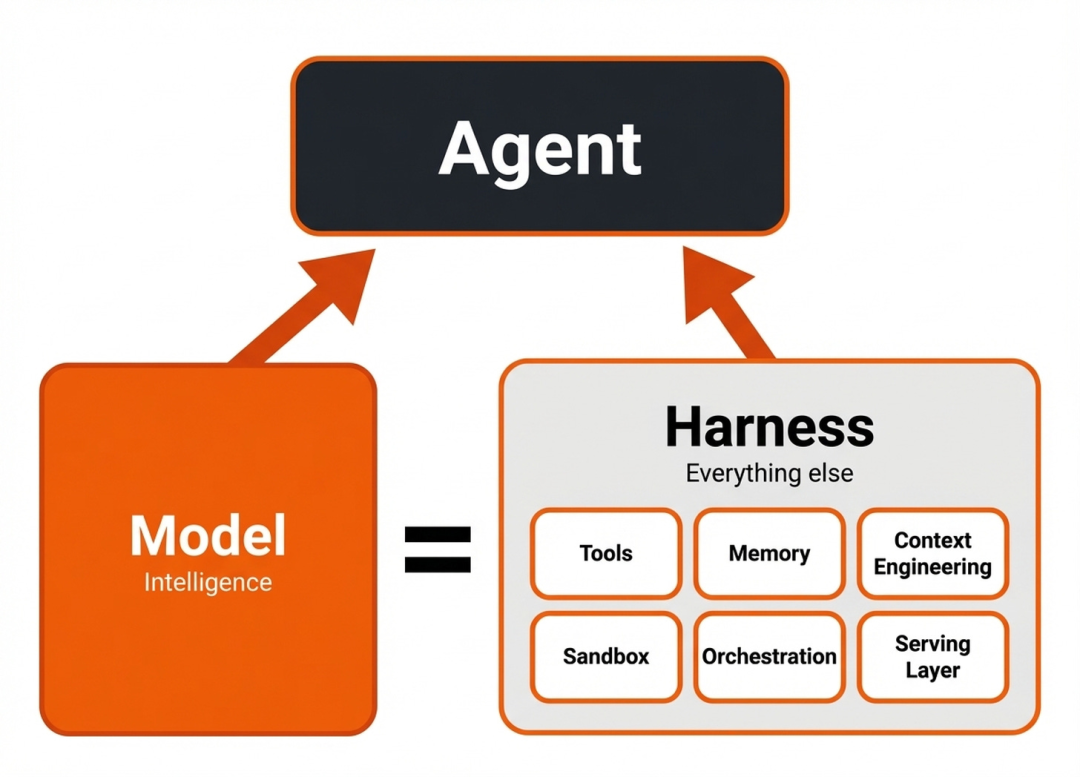
简便来说,模子是大脑,负责念念考「漏洞可能在哪、下一步该怎么挖」。
Harness是四肢加神经系统,负责把大脑的想法形成一连串真实动作——
掀开哪个文献、跑哪条敕令、拿到报错后怎么养息、上一轮失败了下一轮怎么改。
在CyberGym这种要跑几十上百轮、要在百万行代码里反复试错的任务上,Harness的横暴,直接决定了模子的智力能不可改变成战役力。
一个机灵的模子 + 一个普通的Harness,限度经常是「想得回、作念不到」;
一个智力塌实的模子 + 一个为漏洞挖掘量身打造的强Harness,才可能在这种长程任务上跑出获利。
为漏洞挖掘「量身定制」的Agent
如今,透过GitHub技巧论述,MopMonk的技巧端倪,果决了了:
一款专为漏洞挖掘全新遐想的安全多Agent系统,而扶植其运转的念念维基座,正是MiniMax M3。

GitHub地址:https://github.com/MopMonkAI/MopMonkAgent
如前所述,M3是当下生僻的、能将顶尖编码智力、百万token高下文与原生多模态集于单一架构的开源模子。
看一眼跑分就能倡导:SWE-Bench Pro斩获59.0%、Terminal-Bench 2.1达到66.0%、MCP Atlas拿下 74.2%——
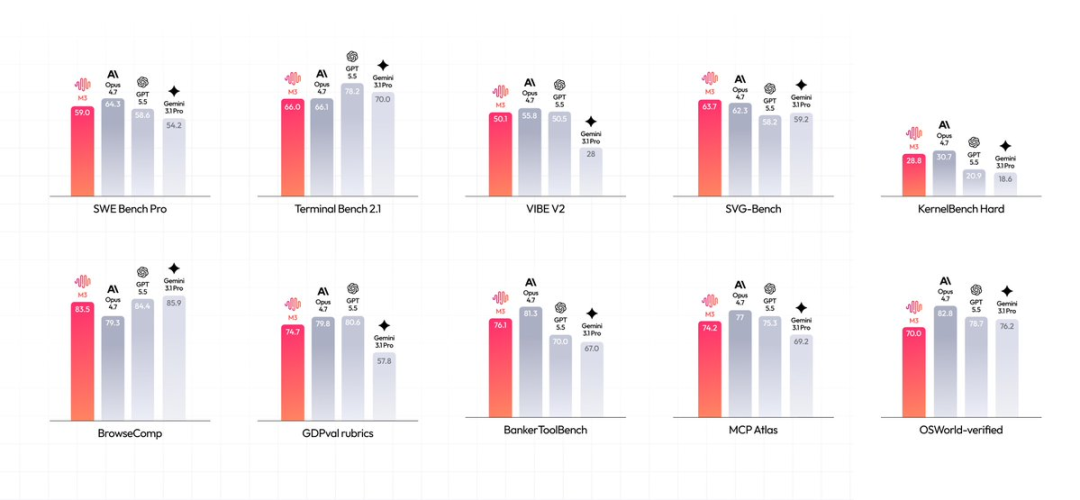
这些亮眼的数据,精确踩中了Agent落地实战时,最硬核的智力刚需。
不仅如斯,它还能在长达十几个小时的任务里自主迭代、自我纠错。
换言之,M3上演了一颗兼具顶尖代码贯通力、超长操心力与熟练用具调用智力的「最纷乱脑」。
关于CyberGym这种动辄要吞下所有这个词代码库、跑上几十轮的任务,1M的高下文窗口险些是刚需。
而MopMonk这套安全Agent框架作念的事,是把M3这颗大脑的智力,放大成漏洞挖掘的实施力。
它的「内功心法」,从GitHub公开的技巧细节来看,中枢是三招——
第一招,结构化的「漏洞操心」。
它不是简便堆叠聊天记载,也不是把超长高下文一股脑塞给模子,而是把一份可不息更新的「任务事实操心」,围绕漏洞挖掘里最要津的几类对象组织起来:
漏洞指标、代码旅途、输入神气、候选PoC、失败根据、考证情状,以及「下一步护士」操心。
临了一类尤其见功力:它不生成清贫的详尽狡计,而是直接从面前根据里,提取出下一次推行必须舒适的硬护士。
比如,「此次必须覆盖到阿谁分支」「该养息哪个字段」「要摈斥哪一类失败原因」。
这种操心遐想,将漏洞挖掘从「反复从零试错」形成了「基于根据的敛迹经由」。
每一次读代码、每一次实施限度、每一次失败提交,都被改变成下一步生成PoC可复用的护士。

第二招,操心驱动的「漏洞挖掘」。
在漏洞挖掘任务中,系统治先通过扫描代码库,并将候选触发旅途和目次信息作为狡计的开端,来开动化漏洞操心。
然后,它一步步推动,试图敛迹到触发崩溃的具体代码位置。
之后,每一次探索尝试都会读取面前操心,测试一个具体的假定,并将限度写回操心中。
这样一来,模子无谓每一轮都从新重读所有这个词任务,而是从这份结构化操心里,精确调出当下最关联的那一小块根据——
既大幅裁汰了长高下文的背负,又让候选PoC的每一次变异,都能接管此前积聚的代码旅途与输入神气常识,让搜索越收越准。
在严格的探索预算内,时刻于是被尽可能地花在「新假定」上,有用测验密度直线拉升。
第三招,分享操心下的「多Agent并行探索」。
多个探索尝试,分享并吞份漏洞操心,不错从补丁陈迹、harness进口、文献神气字段、sanitizer类型、范围条目等多个宗旨同期推动,并彼此接管失败申饬与考证限度。
这既扩大了覆盖面,又幸免了疏通无效的探索。
由此看出,MopMonk把漏洞复现,从一场绽开式的反复试错,硬生生重写成了一个「可积聚、可护士、可考证」的操心更新经由。
三招合一,全凭在职务里面少量点千里淀、提取、复用出来的「内功」,硬生生把一颗纷乱的开源基座,调换成了漏洞挖掘战场上的特战标兵。
最终,它跑出了73.1%的得胜率。
基座负责「想得深」,Harness负责「谨记牢、调得准、打得稳」。
两者深度耦合,才最终铸就了榜单上阿谁令东说念主留神的破局获利。
一个比「堆参数」更有价值的判断
这件事真实的启发在于——
往时几年,行业的惯性是「堆参数」:参数越大、模子越强、榜单越高。
但CyberGym这种真实攻防任务给出了另一种谜底:决定赢输的,越来越是Agent的实施智力,是Harness这层工程的厚度。
根据GitHub技巧论述,这套款式的价值落在三点上:
纷乱的基模智力,提供了搜索的基础;
结构化的漏洞操心,提供了敛迹的机制;
分享操心的多智能体探索,在有限预算里提高了老本后果。
基座决定了智力的上限,而这套操心中心的Harness,决定了这份智力到底能实现若干。
更要命的是它的复利属性:
模子基座会一代代换,今天用M3,未来可能用更新的开源模子。
但一套被真实战场反复打磨、千里淀了攻防申饬的Harness,是不错跳跃基座迭代、不息复利的钞票。
简而言之,MopMonk Harness的恒久价值,可能比「再堆一倍参数」更大。
这正是业内动手追究注视,这个玄妙「扫地僧」的根柢原因:
大家想看的,不仅仅它打了若干分,而是它示范了一条把开源基座作念到极致的路。
是以,「扫地僧」到底是谁?
绕了一圈,咱们如故回到了阿谁最动手、也最让东说念主抓心挠肝的问题。
MopMonk,到底是谁?!
把陈迹拼起来:东方武侠味拉满的代号 + 上海公司的MiniMax基座 + 零丁安全范围的「内功」。
险些所有箭头,都指向并吞个判断:这是一支来自中国、很可能就在上海的AI安全公司。
也有东说念主顺着基模与Agent双向适配的角度,盲猜其背后与AI大模子原生团队脱不开关系。
各式版块的猜想在坊间疯传,但于今无东说念主能甩出实锤。
你以为火星电竞·(CHINA)官方网站,MopMonk会是谁家的高东说念主?考虑区,等你来爆料。